

H-Optimus-1 is current — a 1.1B-parameter vision transformer (ViT-g/14) trained with self-supervised learning on billions of tiles from over 1 million slides of more than 800,000 patients, spanning 50+ organs, 3 scanner types, and 4,000+ clinical centers. As of May 2026 it ranks #1 on the public PathBench leaderboard and is the top image-only model on HEST. H-Optimus-0 (2024) is the previous generation, open-source under Apache 2.0. See Benchmarks and the Hugging Face model details.
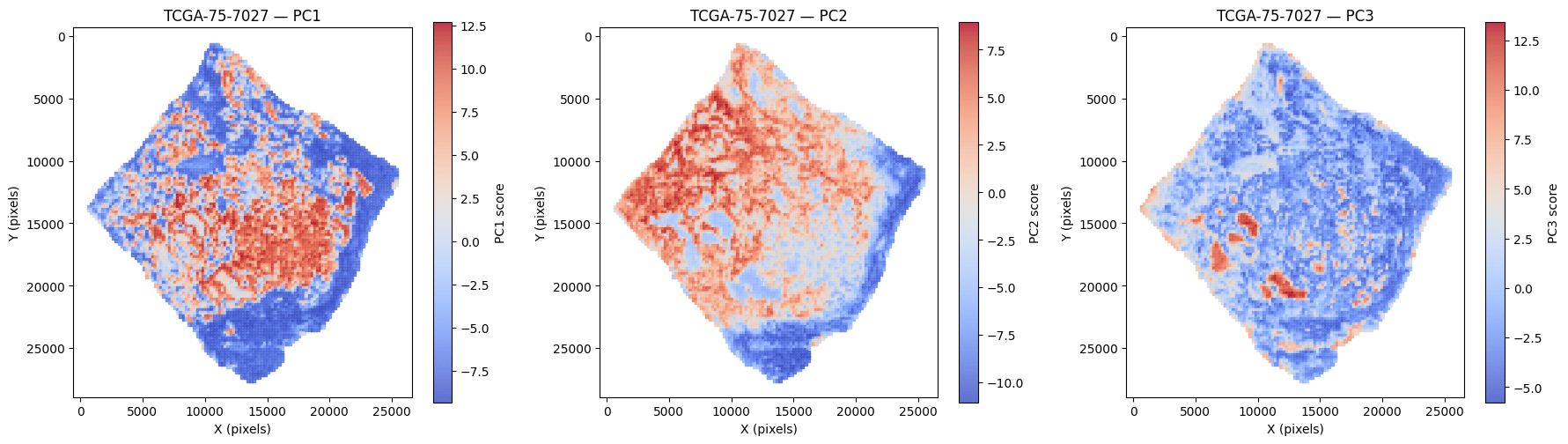
Spatial PCA of tile embeddings on a TCGA-LUAD slide (TCGA-75-7027) — PC1–PC3 each isolate a distinct tissue region (e.g. tumor epithelium, stroma, immune infiltrate). H-Optimus and M-Optimus share the same 1536-d embedding space. Representative example.
Specifications
How it’s used
1
Segment tissue
Run tissue segmentation to keep tissue-bearing tiles.
2
Extract features
Embed 224×224 tiles to get a 1536-d vector each (the SDK tiles and dispatches for you).
3
Build downstream models
Aggregate embeddings for slide-level prediction, retrieval, or classification.
Deploy
H-Optimus runs on AWS SageMaker, on-premise, or Hugging Face (academic). See the Deployment overview for the full comparison and setup steps.Guides
Tile embeddings & PCA
Extract embeddings and visualize morphology.
Bioptimus SDK
Run whole-slide inference with the Bioptimus SDK.